即是知识回顾,也是最近学到知识的拓展延伸。
ARMv6 Manual: “The only architecturally-guaranteed way to invalidate all aliases of a physical address from a VIPT instruction cache is to invalidate the entire instruction cache.”
Cache 的基本情况
Cache 也就是缓存,作为高速的 CPU 和低速的内存之间的缓冲,用于加速访问。
一个内存地址一般分为三个部分,由高到低分别为 tag, index 和 offset 。index 用于索引缓存行,offset 用于确定在缓存行的位置。
为什么需要 tag 呢?这是因为缓存的大小是远远小于内存大小的,所以不同的 index 可能对应同一个缓存行,所以需要使用 tag 来区分。
那为什么 tag 是高位,而 index 是低位呢?这是因为一般情况下访问的内存都是若干块连续的,处于不同块的内存地址低位可能重复而高位不重复。
有三种 Cache 组织方式,分别是全相连、组相连和直接相连,其中全相连不划分 index ,直接比对 tag 。
多级 Cache
为了进一步提升访存速度,人们引入了多级 Cache 。现代 CPU 一般有 3 级,以 Cortex-A53 为例,它的 L1 cache 是 CPU 私有的,L2 cache 是同一个 cluster 共享的,L3 cache 是所有 CPU 共享的,并以总线与内存相连。
icache/dcache 及其一致性
在 L1 或者 L2 cache 中,一些 CPU 会将 cache 分为 instruction cache 和 data cache 。这有两个考虑,一是性能,二是成本。本质原因是 CPU 对指令和数据的访问方式不同,指令一般是只读的,不需要把电路设计得非常复杂。
不过现实还是比较残酷的,很多时候 icache 是不能保证只读,比如 GCC 调试打断点的时候就会修改指令,它先将数据加载到 dcache 中再修改,这时就需要解决 icache 和 dcache 的一致性问题。
MMU 和 TLB
MMU 是 Memory Management Unit ,用于将把虚拟地址转换为物理地址。Linux 中的页表一般是四级的,也可以配置为五级。从高到底分别为:
- PGD:page Global directory(47-39), 页全局目录
- PUD:Page Upper Directory(38-30),页上级目录
- PMD:page middle directory(29-21),页中间目录
- PTE:page table entry(20-12),页表项
这解决了利用少量页面数据管理大量内存的问题,但是也会让一次查询需要在内存中查四次页表,大大降低了访存速度,所以 MMU 中也需要一个类似 Cache 的存在,那就是 TLB 。TLB 的访问速度比 L1 还要快,和寄存器相当。
由于页面大小一般为 4KB ,因此 TLB 不需要管最低的 12 位。而且 TLB 的一个 entry 只存一个物理地址,所以也不需要类似 cache 的 offset 字段,虚拟地址只需要分成 tag 和 index 两个部分。
VIVT vs VIPT vs PIPT
这里的 V 代表 virtual , P 代表 physical , I 和 T 分别代表 index(ed) 和 tag(ged) 。
前面说了通过 tag 和 index 在 cache 中查找,但是这里的 tag 和 index 位于虚拟地址还是物理地址呢?
歧义和别名
我们也可以先注意两个问题:歧义(ambiguity)和别名(aliasing)。
- 歧义指不同的数据有相同的 tag 和 index ,从而导致无法区别。
- 别名指不同的虚拟地址映射相同的物理地址(这在 Linux 中很常见),这容易导致 cache 的数据不一致问题。
VIVT
这种 index 和 tag 都取自虚拟地址的方法又叫虚拟高速缓存。在这种情况下,只要 cache 命中,就不需要进行地址翻译,这提升了速度,也设计简单。
但是这样的设计暂时还不能解决 ambiguity 和 aliasing 问题。
想要解决 ambiguity ,可以在每次切换进程的时候 flush 所有的 cache ,但是这样又会导致大量的 cache miss 。
想要解决不同进程的 aliasing ,也可以在每次切换进程的时候 flush 所有的 cache 。
如果是同一个进程的 aliasing ,就没有很好的办法了。
PIPT
这种 index 和 tag 都取自物理地址的方法又叫物理高速缓存。这样的设计可以让操作系统少操心,完全避免了 ambiguity 和 aliasing 问题。
虽然 PIPT 在软件层面基本不需要维护,但是硬件设计上比 VIVT 复杂很多,成本也更高。而且由于虚拟地址每次都要先翻译成物理地址,因此在查找性能上低于 VIVT 。
VIPT
在索引 cache 时,可以使用虚拟地址的一部分作为 cache 的inde 。而 cache 的 tag 则使用物理地址中的 PFN (独一无二,后文也会说到)。这种方法的好处是,TLB 翻译得到 PFN 和 index 索引 cache 是同时进行的。
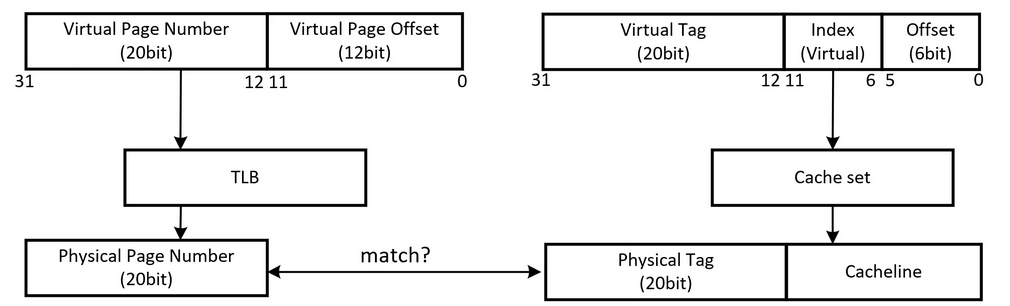
为什么没有歧义问题?
我们可能有种思维惯性, tag 就是地址的一部分,和 index 合在一起才能成为一个低 offset 位为 0 的地址。这种说法在 VIVT 中是对的,但是在 VIPT 中是错的。tag 本来就是标签的意思,只是用于区分相同 index ,它并不意味着它是减去 index 的那些位。 只是在 cache 的查询中, tag 和 index 没有重合而且合起来刚好覆盖了地址中除了 offset 的位。
现在再看 MMU ,一般情况下 64 位地址只用了低 48 位表示地址,而一个页面一般是 4KB 。这样一来, MMU 只需要将 47 位到 12 位进行地址映射,这和 VIVT 的 index 和 tag 的那些位是不同的。
既然都使用了 MMU 把虚拟地址的全部位翻译成了物理地址,那么为什么还要取物理地址中和 VIVT 中的 tag 一样的位呢?所以 VIPT 使用这 47 位到 12 位作为 tag ,这些 tag 是独一无二的,可以完全避免 ambiguity 的问题。
什么时候没有别名问题?
可以发现, VIPT 虽然没有直接解决别名问题,但有些情况下可以避免别名,那就是 cache size 除以路数小于 page 大小时。即 index + offset <= 12bit 不会发生重名,即只要 cache 每一路小于等于 4KB ,就不会发生重名。即 4KB 直接映射、 8KB 两路组相联、 32KB 八路组相联等,都不会有问题。此时 VIPT 的功能和 PIPT 一致,但速度和 VIVT 一致,可以说综合了两者的优点。
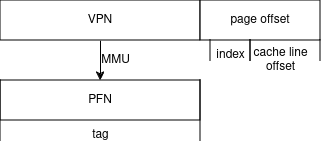
但是,当 index + offset > 12bit (页面大小为 4KB )时,对应同一个物理地址的两个虚拟地址可能被分配到两个 cache set 中,就出现了重名现象。
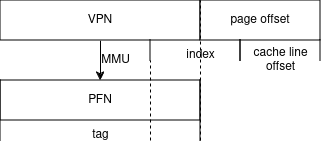
如果无法避免别名,如何解决?
很多 CPU 的 L1 dcache 都遵循了上述的 cache 每一路小于 4KB 的规律。但是继续增加 cache size 的同时继续增加相联度会导致过于复杂的时序。此时,我们不得不增大 cacheline 和增加组数,最后导致 index + offset > 4KB 。
解决办法其实也很简单,可以在操作系统层面上创建共享内存的时候地址要按照一路 cache size 对齐,这样就完全避免了别名问题。这也就是 page coloring 技术。它相当于将一路 cache 按照 page 的大小切分了。
例如 page size 是 4KB ,而一路 cache size 是 16 KB ,则我们可以将页面按顺序填上 16 / 4 = 4 种颜色,只有颜色相同的虚拟页面才能分配到对应的物理地址上,这也就做到了按照一路 cache size 对齐了。
对于上例,一些 CPU 的做法:
- 最简单的方法是确保给定虚拟地址的第 12 位和第 13 位(也就是 VPN 的低两位)与相应物理地址中的相同位匹配。即相当于将页面大小改大为 16KB ,这需要 CPU 支持修改 MMU 粒度。
- 如果仅使用 4KB 页面,则可以构建保留颜色限制的映射,并允许虚拟地址和物理地址之间的第 12 位和第 13 位不同。这种做法会增加额外的复杂性。
- 硬件方法解决,例如 香山架构 。

现代 CPU 的选择
多数的选择
绝大多数 CPU 的 L2 L3 都是 PIPT 的,不同点在于 L1 cache 的设计。
L1 cache 的 dcache 和 icache 可以采用不同的设计,分别选用 VIPT 或者 PIPT 。很多 CPU 的 L1 dcache 使用的是 PIPT 而 icache 是 VIPT 。
少数 VIVT 的 L1 设计
传统上,虚拟地址的缓存有很多缺点:它们会在上下文切换或 TLB 维护操作时被刷新,因为更改虚拟地址到物理地址的映射意味着一个虚拟地址的缓存的内容不再是最新的。
但是可以通过引入 ASID (标记不同进程)来避免上下文切换时刷新,还可以通过记录 VA 到 PA 的别名来解决别名问题。
趣事:ARM 与 mmap
ARMv6 和 ARMv7 执行相同的 mmap 代码会有不同的结果, v6 会失败,而 v7 会成功:
// Preconditions:
// - fd is a file descriptor as returned from open() (or a related function).
// - The file is at least 4096 bytes long (and so can fill the mapping).
// - The file's permissions are compatible with those in the mmap calls.
// - MAP_FIXED is supported.
// - The addresses provided can be mapped by the process, and are not
// allocated or otherwise reserved or invalid.
void * buffer0 = mmap((void*)(0x12340000), 4096, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_FIXED, fd, 0);
void * buffer1 = mmap((void*)(0xdebc1000), 4096, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_FIXED, fd, 0);
这段代码将文件映射到了两种颜色的虚拟地址上,可以看到 0x12340000 的第十二十三位是 00 ,而 0xdebc1000 的第十二十三位是 01 ,这违背了 page coloring 的原则。
两代架构执行代码的结果不同是因为:v6 的 dcache 是 vipt 的,而 v7 的 dcache 是 pipt 的,所以 v7 不存在别名问题,而 v6 存在。