前因
最近看了一篇介绍 Ventana 的 Veyron V1 核心的博客 HotChips 2023: Ventana 不寻常的 Veyron V1 ,里面出现了很多我没听说过或者不甚了解的名词,在阅读这篇博客和查找资料的过程中,我学到了很多新的 CPU 知识。
BTB 是什么?
BTB 即分支目标缓冲(Branch Target Buffer),本质上是 Cache ,通过当前 PC 的一部分进行索引,与 entry 中的 tag 进行比对,输出的是 target address 。
BTB 解决的是什么问题呢?解决的是如何快速定位跳转地址的问题。但是,跳转的地址一般就在指令中,取出来几乎是无延迟的,那为什么需要快速定位呢?原因在于分支预测在取指阶段之前!只有先做预测才能快速取出多条指令进行译码。
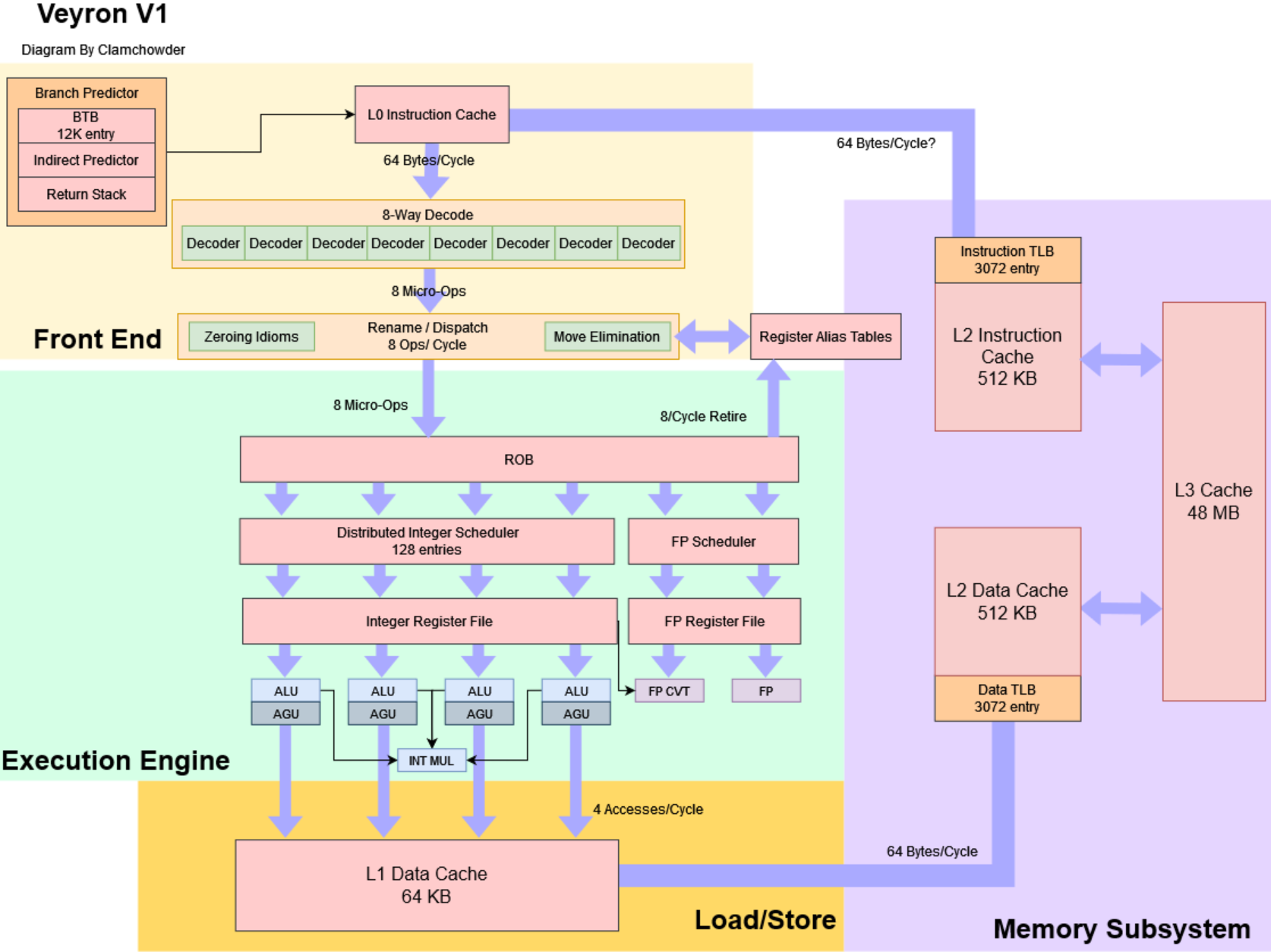
2-bit 饱和计数器是什么?
解决了跳转地址的问题还需要解决是否跳转的问题,这个一般叫做 Taken / Not taken ,这也是分支预测的核心。
分支预测的前提是程序执行顺序有一定的规律,或者说有一定的惯性,所以有人就设计出来了 2-bit 饱和计数器:
- 之所以叫 2-bit 是因为它有四种状态:strongly taken, weakly taken, weakly not taken, strongly not taken 。每次 actually taken 了,状态就将向左迁移;每次 actually not taken ,状态就将向右迁移。
- 之所以叫「饱和」是因为当处于 strongly (not) taken 状态时再 (not) taken 不会再迁移状态。
2-bit 饱和计数器是如今分支预测方案的基础,但是单纯只使用它会导致在一些极端条件下性能很低。举一个很简单的例子 NTNTNTNT… ,它的准确率只有 50% ,这显然是不可接受的。
BHR 是什么?局部历史分支预测器是什么?
BHR 即分支历史寄存器(Branch History Register),它的出现是为了配合 2-bit 饱和计数器来提高预测准确率。
BHR 是一个 n 位的可以不断左移的寄存器,用于存储 n 次分支跳转结果。
一个 BHR 对应 2^n 个 2-bit 饱和计数器,这样的一组饱和计数器被称为 Pattern History Table(PHT) 。可以想到,此时的分支预测就是通过 BHR 的值来索引 PHT 的计数器。
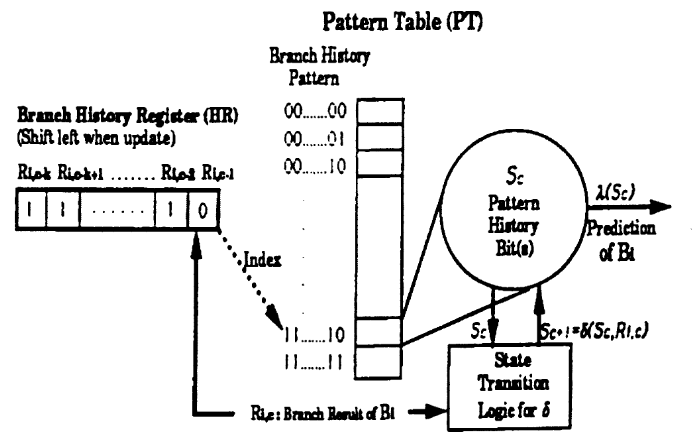
以之前提到的 NTNTNTNT… 这个极端情况为例,假设 BHR 的宽度为 2 ,它会在 10 和 01 之间交替,分别对应了两个计数器,一个会饱和于 taken ,另一个则会饱和于 not taken 。这样一来就完美解决了之前的问题。
整体的工作流程就是:首先通过 BTB 找到分支 PC ,再通过分支 PC 找到对应的 BHR ,最后通过 BHR 在 PHT 中查找,决定是否 taken 。
PHT/2-bit counter 何时更新?
现代 CPU 一般都是超标量的,每次可以取出不止一条指令送入流水线中进行乱序执行。为了保证结果的正确性,必须在 commit/retire 阶段更新,此时不会再因为分支预测的错误导致流水线 flush 。
但是分支预测一般是流水线的第一个阶段, commit/retire 是最后一个阶段。这样一来,预测和更新之间间隔时间过长,在这个间隔时间内这条指令可能已经按照之前的 counter 状态执行多次了,这好像失去了时效性。但其实不需要担心,这种情况一般发生在循环体很短的情况下,由于饱和计数器的性质,它在几次后就会成为 strongly taken 状态,由于已经饱和,不及时更新也没有关系。
BHR 何时更新?
一般情况下 BHR 的更新也是在 commit/retire 阶段的。这也是因为如果在其他阶段会遇到正确性问题,需要额外开销来恢复(或者说修正)。
BHR 同样不用担心间隔时间过长,原因和上面的 PHT 一样。
GHR 是什么?全局历史分支预测器是什么?
这一设计的假设是分支的结果之间互相关联,这在我们日常写的代码中有很多体现,显然是很有道理的。
这样就只需要一个 Global Branch History Register ,记录所有分支在过去的执行结果。
GHR 何时更新?
GHR 应当在分支预测后更新,因为两个邻近的分支指令会间隔很短的时间进入流水线,GHR 如果不在分支预测后更新便失去了意义,违反了「分支的结果之间相互关联」的假设。
分支预测错误了,但是后续的分支指令使用了错误的 GHR 怎么办呢?不用管,因为后续的指令都应该被流水线 flush 掉。 不过,还是需要额外的开销来恢复 GHR 。
Aliasing PHT 是什么问题?
由于所有的分支使用同一个 PHT ,因此容易出现不同分支指向同一个 PHT entry 的问题。解决方案有很多:
- 最简单的方法是增大 PHT ,使用 PC 中更多位来寻找 entry ,这会增加面积和功耗。
- 还有就是使用 hashing/index-randomization ,比如 Tage(TAgged GEometric history length),最简单的方法是将 GHR 和 PC 进行异或操作后再寻址,香山架构就使用的是这个方法。以此思想还有很多 hash 设计来防止碰撞。
Warmup/Training time 是什么?
PHT entry的计数器达到饱和状态的时间称为 training time ,它和 BHR/GHR 的长度有关,较长的 BHR/GHR 需要更多的时间 warmup ,但也会记录更多的历史信息,提高预测准确度。较短的 BHR/GHR 不能记录分支的所有结果。
现代 CPU 很多都是超标量的,下一条分支指令开始预测时上一条分支指令可能还远远没有执行结束。为了尽快拿到分支历史,大部分分支预测机制都会选择「推测更新历史」,也就是上文中说到的在分支预测后立即更新 GHR 。
全局历史分支预测 > 局部历史分支预测?
记得之前说过全局分支预测只需要一个 GHR 而局部分支预测需要一组 BHR 吗?这会引起存储介质选择的问题,一个 GHR 再怎么长都可以直接用寄存器存,而一组通过 PC 索引的 BHR 表相对较大,只能用和缓存一样的 SRAM 来存。
使用 SRAM 来存的问题在于,恢复历史时无法在一拍内恢复或者甚至无法在短时间内恢复。这种维护的困难使得局部历史在现代处理器的分支预测器中很少见到。
更高级的分支预测机制
- 将局部和全局历史分支预测结合 The Alpha 21264 Microprocessor Architecture。
- 预测循环,即使用通过计数避免最后一次循环预测错误。
- 引入机器学习的方法。