继续学习 OpenMP 的使用,尤其是一些较新版本。
OpenMP 4.0
Controlling OpenMP thread Affinity
因为很多硬件如今是 NUMA 结构,分配线程的位置可以很大程度上影响性能。
与核绑定有关的 OpenMP 结构 proc_bind (master | close | spread)
- master
继承串行部分的核绑定,用运行之前串行线程的核来执行所有的线程。
- close
优先分配与串行线程相临近的核。当并行线程数量大于核心数量时,分配方式与 spread 相近。
- spread
稀疏、均匀地进行绑定。如果有 M 个线程, N 个核心,那么从串行线程运行的那个核开始分布,每个核上运行 $M/N$ 个线程。
Task constructor
OpenMP 4.0 可以指定 task 之间的依赖关系。
taskwait
int fib(int n) {
int i, j;
if (n < 2) return n;
else {
#pragma opm task shared(i) firstprivate(n)
i = fib(n - 1);
#pragma omp task shared(j) firstprivate(n)
j = fib(n - 2);
#pragma omp taskwait
return i + j
}
}
int main(void) {
int n = 10;
opm_set_num_threads(4);
#pragma omp parallel shared(n)
{
#pragma omp single
printf("fib (%d) = %d\n", n, fib(n));
}
return 0;
}
上述代码中的 taskwait 指令可以保证在 return 之前要计算完成 i 和 j 。
虽然只有一个线程会执行 fib 的调用,但是在 fib 函数之中的 task 执行是四个线程都参与的。
Task dependencies
对同一父级任务的调度增加额外的约束。
#pragma omp task depend(type: list)
type := in | out | inout
类似于依赖图。
- Flow dependency: read - after - write(RAW)
int x = 1;
#pragma omp parallel
{
#pragma omp single
{
#pragma omp task shared (x) depend (out: x)
x = 2;
#pragma omp task shared (x) depend (in: x)
printf("x = %d\n", x);
}
}
- Anti dependency: write - after - read(WAR)
int x = 1;
#pragma omp parallel
{
#pragma omp single
{
#pragma omp task shared (x) depend (in: x)
x = 2;
#pragma omp task shared (x) depend (out: x)
printf("x = %d\n", x);
}
}
- Output dependency: write - after - write(WAW)
int x = 1;
#pragma omp parallel
{
#pragma omp single
{
#pragma omp task shared (x) depend (out: x)
x = 2;
#pragma omp task shared (x) depend (out: x)
printf("x = %d\n", x);
}
}
上述代码中的两个 task 可以以任意方式执行,因此可能会出现数据竞争的情况。
在矩阵中使用,利用数组分片。
以下例子展示了一个基于 task 的矩阵(N * N)分块,分成 BS * BS 的分块矩阵。
// Assume BS divides N perfectly
void matmul_depend(int N, int BS, float A[N][N], float B[N][N], float C[N][N))
{
int i, j, k, ii, jj, kk;
for(i = 0; i < N; i += BS)
for(j = 0; j < N; j += BS)
for(k = 0; k < N; k += BS) {
#pragma omp task \
depend (in: A[i:BS][k:BS], B[k:BS][j:BS]) \
depend (inout: C[i:BS][j:BS])
for(ii = i; ii < i + BS; ii++)
for(jj = j; jj < j + BS; jj++)
for(kk = k; kk < k + BS; kk++)
C[ii][jj] = C[ii][jj] + A[ii][kk] * B[kk][jj];
}
}
Taskyield construct
使当前的 task 让出,方便其他的 task 执行。一般和 while 语句搭配使用:
for (int i = 0; i < N; ++i) {
#pragma omp task
{
something_useful();
while (!omp_test_lock(lock)) {
#pragma omp taskyield
}
something_critical();
omp_unset_lock(lock); // 释放锁
}
}
Taskgroup Construct
taskwait vs. taskgroup
- taskwait 只 join 子任务
- taskgroup join 所有子任务和子任务派生的任务
User define reductions
#pragma omp declare reduction(reduction-identifier: typename-list: combiner) [initialize-clause]
- reduction-identifier: 可以是一个用户定义的操作,也可以是 +, -, *, &, |, ^, &&, ||
- typename-list: 操作作用的变量
- combiner: 指定如何结合这些变量的语句

#include <math.h>
void reduction1(float *x, int *y, int n)
{
int i, b, c;
float a, d;
a = 0.0;
b = 0;
c = y[0];
d = x[0];
#pragma omp parallel for private(i) shared(x, y, n) \
reduction(+:a) reduction(^:b) \
reduction(min:c) reduction(max:d)
for (i=0; i<n; i++) {
a += x[i];
b ^= y[i];
if (c > y[i])
c = y[i];
d = fmaxf(d,x[i]);
}
}
Construct cancellation
#pragma omp cancel construct [if (expr)]
constructor := parallel | sections | for | taskgroup
int t = 1;
#pragma omp parallel firstprivate(t)
{
#pragma omp for
for (int i = 0; i < 100; ++i) {
t = test();
#pragma omp cancel for if (t == 5)
}
#pragma omp cancel parallel if (t == 5)
#pragma omp barrier
printf("Thread %d\n", omp_get_thread_num());
}
cancel 功能默认是关闭的,如果需要则要把环境变量 OMP_CANCELLATION 设置为 true,$OMP_CANCELLATION=true ./test
SIMD Constructs
OpenMP 对并行和串行都有向量化支持。
#pragma omp simd [clauses]
可以对循环使用,指示这个循环迭代可以 SIMD 分块执行
#pragma omp declare simd [clauses]
标记这个函数可以被一个 SIMD 循环调用
#pragma omp for simd [clauses]
表示循环可以分块后被线程组执行,每一块都可以 SIMD 向量化
#pragma omp declare simd
double inc(int i)
{
return i + 1;
}
int main(void)
{
int d1 = 0, N = 100;
double a[N], b[N], d2 = 0.0f;
#pragma omp simd reduction(+: d1)
for (int i = 0; i < N; ++i)
d1 += i * inc(i);
#pragma omp parallel for simd reduction(+: d2)
for (int i = 0; i < N; ++i)
d2 += a[i] * b[i];
}
Device Constructs
OpenMP 4.0 开始支持异构计算,可以将计算部分放到其余的 target 上完成。
在 map 语句中,有两种映射类型,分别是 to 和 from,定义了 original(host) 和 target(device) 之间的数据映射
- to: 在 device 上只读
- from: 在 device 上只写
通过限制数据的权限,可以减少数据传输中的开销。
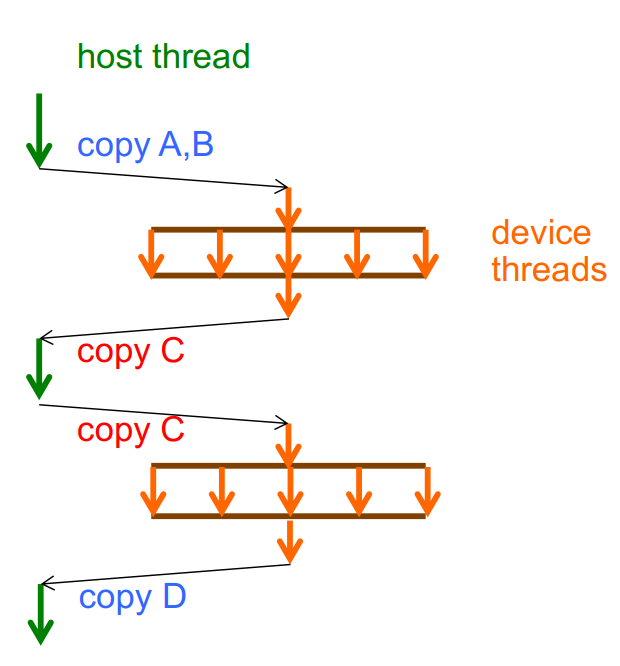
#pragma omp target data
为后面的代码域创建一个 device 数据环境,它的作用只是将数据移动到 target 上。
void vec_mult(float *p, float *v1, float *v2, int N)
{
int i;
#pragma omp target data map(to: v1[0:N], v2[0:N]) map(from: p[0:N])
{
#pragma omp target
#pragma omp parallel for
for (i = 0; i < N; ++i)
p[i] = v1[i] * v2[i];
}
output(p, N);
}

#pragma omp target
创建一个 device 数据环境,并在这个 target 上执行之后结构中的语句。
#pragma omp target update
在 target 域中更新数据
#pragma omp target update to(v1[:N], v2[:N]) // 将新值分配给 target 环境
#pragma omp declare target
指示变量或者函数被映射到了 device 上。
#pragma omp declare target
extern void fib(int N);
#pragma omp end declare target
#define THRESHOLD 1000000
void fib_wrapper(int n)
{
#pragma omp target if (n > THRESHOLD)
{
fib(n);
}
}
OpenMP 4.5
Parallelism & Workshare for devices
- omp teams [clause[[,] clause], …] newline structured-block
- omp distribute [clause[[,] clause], …] newline for-loops