最近看到了一些关于侵入式和非侵入式链表的讨论,决定研究一下它们两个。
侵入式和非侵入式链表的区别
这里的侵入是相对于链表的指针域来说,所以最主要的区别就是非侵入式的链表容器中保存了一份用户传入的值。
class list_node {
list_node *next, *previous;
MyClass value;
};
可以看到非侵入式的链表在分配节点时要包含指针域和数据域。
而侵入式链表就不需要保存传递对象的拷贝,而是保存对象本身。对象插入链表中的所需要的附加数据由对象本身提供。
可以看 Linux 提供的listnode结构体:
struct listnode {
struct listnode *next, *prev;
};
使用时,需要将一个listnode结构体放入到需要组成链表的结构体中:
struct data {
int a;
int b;
char *c;
struct listnode _list;
};
在使用的时候,可以用一些宏来方便代码书写,尤其是在通过listnode来寻找整个data结构体时,就需要利用偏移量(使用offsetof关键字)和指针的强制转换的宏。
两种容器的优缺点
非侵入式
优点:
- 简单易操作。
- 每个节点只需要分配一次。
- 每个节点是一个整体,所以生命周期和内存手动管理比较友好。
缺点:
- 一个对象只能属于一个容器,如要共享于两个容器(例如同时放在双向链表和红黑树中),就只能拷贝这个对象或者使用指针间接访问。如果使用拷贝的方法就会降低性能。
- 无法保留原始类型的同时将派生对象存储在STL容器中。
侵入式
优点:
- 不会调用内存分配,可以将动态分配的开销最小化,也在插入和擦除对象时有可预测性。
- 使用很小的代价就可以将同一个对象插入到多个容器之中。
- 迭代的速度很快,内存访问更少,从指针或元素引用到该元素的迭代器的计算是一个常数时间,(
std::list<T*>是线性复杂度)。
缺点:
- 更改对象时时刻要注意是否会带来副作用。
- 需要独立于容器管理对象的生命周期以及内存分配。
- 因为对象可以在从容器被删除之前释放,因此迭代器容易失效。
- 分析使用容器的程序的线程安全性更加困难,因为容器可能会在没有显式调用容器成员的情况下被间接修改。
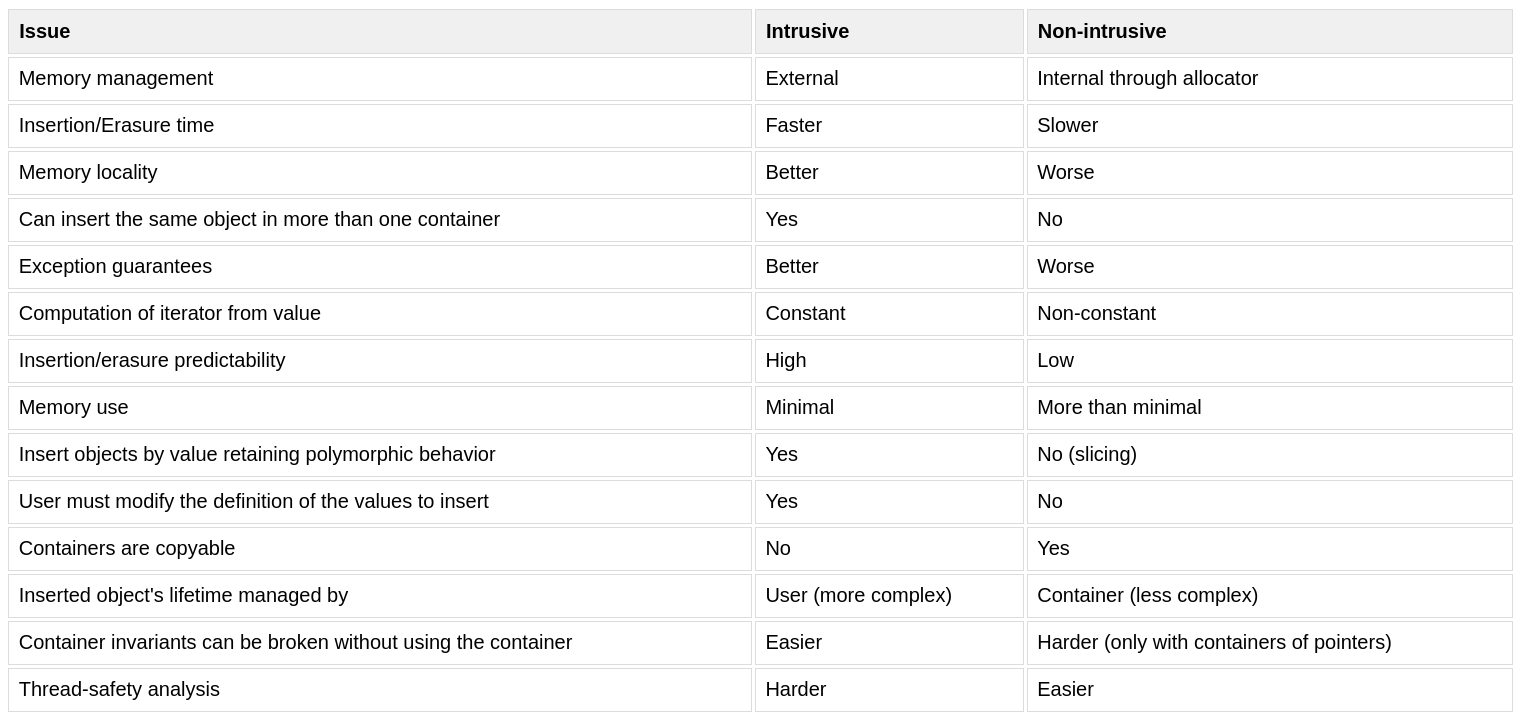
来自 boost 的对比表格