之前学习 Lua 的时候就对它的 Table 很感兴趣,最近在看 Lua 解释器的源码,因此就想研究一下具体是怎么实现这个 Lua 之中最为重要的数据结构的。
Lua Table 简介
在 Lua 语言之中,数组是 table ,字典是 table ,就连对象、模块、包也是通过 table 实现的:
-
数组是键值为正整数的表;
-
由于键值也可以是其他类型,故表也可以实现字典这种数据结构;
-
由于函数也是 Lua 的第一公民,所以成员函数也可以通过表来实现;
-
模块和包之间的从属关系也是通过 table 来表示的。
Lua 中的 table 使用十分广泛,这也导致了 Lua 使用起来有着 纯真的、野性的 简洁的美。
这种数组和字典杂糅的数据结构有是如何实现的呢?这种数据结构又是否高效呢?我们将会在下文进行探究。
Lua 解释器中的哈希函数
传入参数中的 seed 是通过 lua_newstate 函数地址、lua_State 实例的地址和当前时间共同计算得到的,因此具有较强的随机性:
unsigned int luaS_hash (const char *str, size_t l, unsigned int seed) {
unsigned int h = seed ^ cast_uint(l);
for (; l > 0; l--)
h ^= ((h<<5) + (h>>2) + cast_byte(str[l - 1]));
return h;
}
在老版本的 Lua 中 luaS_hash 函数比现在的复杂,是因为新版中只对短字符串使用该函数,而老版本对所有字符串都使用该函数,为了保证求哈希时的效率,所以对字符串大于 32 字节的部分进行跳过至少一个字节的哈希运算(注意 step 变量):
unsigned int luaS_hash(struct lua_State* L, const char* str, unsigned int l, unsigned int h) {
h = h ^ l;
unsigned int step = (l >> 5) + 1;
for (int i = 0; i < l; i = i + step) {
h ^= (h << 5) + (h >> 2) + cast(lu_byte, str[i]);
}
return h;
}
通过 hash 值来得到索引的方法如下:
index = hash_value & ((1U << lsizenode) - 1)
其中 lsizenode 是 node 长度关于 2 的对数,这种方法类似于取模。
Lua 解释器中的重要类型
联合体 Value 能表示 Lua 所有的基本数据结构:
/*
** Union of all Lua values
*/
typedef union Value {
struct GCObject *gc; /* collectable objects */
void *p; /* light userdata */
lua_CFunction f; /* light C functions */
lua_Integer i; /* integer numbers */
lua_Number n; /* float numbers */
} Value;
结构体 TValuefields 的两个字段分别表示 value 和 value 的类型:
#define TValuefields Value value_; lu_byte tt_
typedef struct TValue {
TValuefields;
} TValue;
TValue 长度为 12 个字节,可以使用 NaN Trick 节约空间。
联合体 Node 有两个字段,一个是结构体 NodeKey 依次包含了这个节点的值、键的类型、下一个节点的位置、键的值与类型,另一个字段是 TValue 类型的 i_val ,因为是联合体,所以可以通过直接访问 i_val 得到值的类型和类型:
typedef union Node {
struct NodeKey {
TValuefields; /* fields for value */
lu_byte key_tt; /* key type */
int next; /* for chaining */
Value key_val; /* key value */
} u;
TValue i_val; /* direct access to node's value as a proper 'TValue' */
} Node;
结构体 Table 中 CommonHeader 和 GCObject 与垃圾回收有关,metatable 和元表有关,flags 和元方法有关,都暂时不考虑。lsizenode 是哈希部分长度关于 2 的对数,alimit 是数组部分的长度的下限(不一定是真实大小,是一个估计),array 和 node 分别指向数组部分和哈希部分,lastfree 指向哈希部分存在空槽的末尾位置:
typedef struct Table {
CommonHeader;
lu_byte flags; /* 1<<p means tagmethod(p) is not present */
lu_byte lsizenode; /* log2 of size of 'node' array */
unsigned int alimit; /* "limit" of 'array' array */
TValue *array; /* array part */
Node *node;
Node *lastfree; /* any free position is before this position */
struct Table *metatable;
GCObject *gclist;
} Table;
Table 相关操作
前面已经说到了 Lua 中的 Table 是一个既包含数组部分又包含哈希部分的数据结构,也对 Lua 源码中关于 Table 的类型进行了探究,现在就可以对 Table 的相关操作进行讨论。
在讨论之前有一些前置知识需要了解:首先就是 Lua 的哈希部分应对哈希冲突使用的是链接法,但是它不会单独拉出链表来,依然是一个 Node 数组的形式。它所有的节点都在 Node 数组之中,通过 next 字段串起来,这就导致 Lua 哈希表对内存的利用十分紧凑。
在源码中,作者将键值通过哈希计算直接得到的位置叫做 mainpostion ,下文中称之为主位置。
初始化操作
初始化 Table 较为简单,基本上就是给字段赋值为 0 或者 NULL,但需注意 node 字段并不初始化为 NULL 而是初始化为一个全局变量 dummynode ,这种做法可以减少很多次判空操作。
get 操作
当 key 为一个整数 i_key 时,首先判断 i_key 与 alimit 的关系,如果小于 alimit 说明在数组部分,直接返回下标位置的值;如果大于 alimit 但 alimit 并不是真实的数组大小,就先更新 alimit 再返回下标位置;上述条件都不满足,说明在哈希部分,并在哈希部分查找。
const TValue *luaH_getint (Table *t, lua_Integer key) {
if (l_castS2U(key) - 1u < t->alimit) /* 'key' in [1, t->alimit]? */
return &t->array[key - 1];
else if (!limitequalsasize(t) && /* key still may be in the array part? */
(l_castS2U(key) == t->alimit + 1 ||
l_castS2U(key) - 1u < luaH_realasize(t))) {
t->alimit = cast_uint(key); /* probably '#t' is here now */
return &t->array[key - 1];
}
else {
Node *n = hashint(t, key);
for (;;) { /* check whether 'key' is somewhere in the chain */
if (keyisinteger(n) && keyival(n) == key)
return gval(n); /* that's it */
else {
int nx = gnext(n);
if (nx == 0) break;
n += nx;
}
}
return &absentkey;
}
}
如果 key 不是一个整数,处理方法就较为简单,直接去哈希部分寻找。
set 操作
首先介绍插入键值为一个整数时的情况,此时调用函数 luaH_setint 。插入键值时,先通过上文介绍过的函数 luaH_getint 在 Table 中进行查找,如果不为空则直接 set ,为空则调用函数 luaH_newkey :
void luaH_setint (lua_State *L, Table *t, lua_Integer key, TValue *value) {
const TValue *p = luaH_getint(t, key);
if (isabstkey(p)) {
TValue k;
setivalue(&k, key);
luaH_newkey(L, t, &k, value);
}
else
setobj2t(L, cast(TValue *, p), value);
}
luaH_newkey 是一个很重要的函数,它的主要逻辑和函数原型如下:
/*
** inserts a new key into a hash table; first, check whether key's main
** position is free. If not, check whether colliding node is in its main
** position or not: if it is not, move colliding node to an empty place and
** put new key in its main position; otherwise (colliding node is in its main
** position), new key goes to an empty position.
*/
void luaH_newkey (lua_State *L, Table *t, const TValue *key, TValue *value);
插入一个键值到哈希表中时,首先检查这个键值对应的主位置是不是空的。如果不是空的,就检查那个冲突节点是不是在它自身的主位置上:如果不是,那就调整这个冲突节点到空位置然后将待插入节点放入腾出来的位置;否则(冲突节点在自己的主位置),待插入键值就要去空位置了。
- 冲突节点在自己主位置的情况:
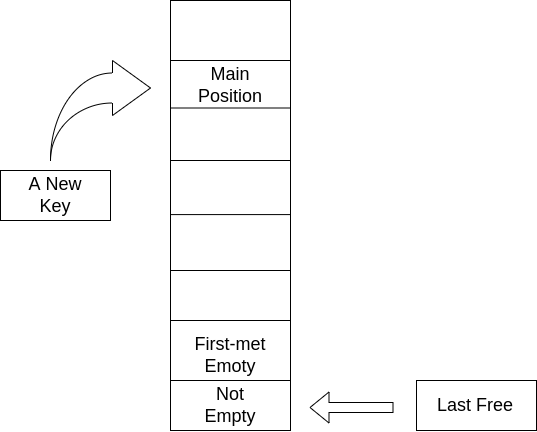
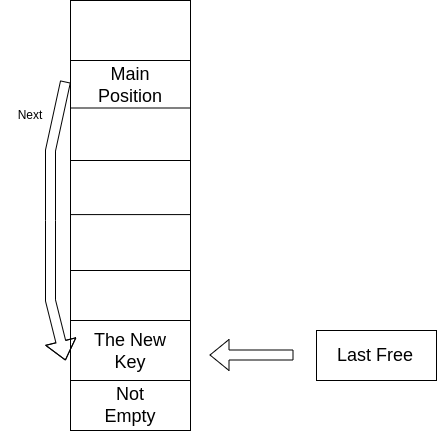
- 冲突节点在自己主位置的情况:
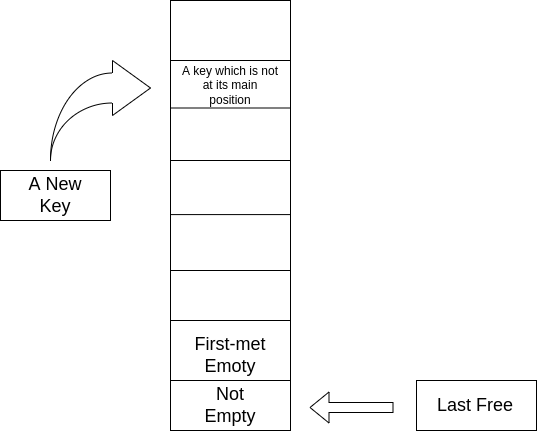
调整不在主位置的冲突节点位置时要把它的前驱的 next 字段进行修改,对冲突节点的 next 字段也要修正。
由于使用链接法时使用的是单向链表,因此想要获取冲突节点的前驱需要将冲突节点的键取出来求哈希,首先得到主位置,再通过一步一步地 next ,找到冲突节点之前的位置。
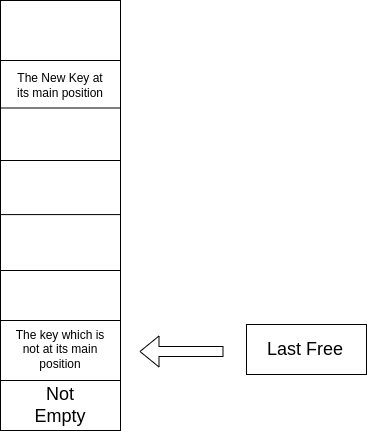
lastfree 的移动:初始化时指向 node 数组的最后一位。在这之后,一般情况下只会使用自减操作向左移动。
resize 操作
当表空间不足时就会进行 resize 操作。
第一步是对 Key 为整数的部分进行统计,统计的是在区间 $(2^i, 2^{i+1}]$ 不为空的元素的个数,方便之后的 resize ,代码如下:
/*
** Count keys in array part of table 't': Fill 'nums[i]' with
** number of keys that will go into corresponding slice and return
** total number of non-nil keys.
*/
static unsigned int numusearray (const Table *t, unsigned int *nums) {
int lg;
unsigned int ttlg; /* 2^lg */
unsigned int ause = 0; /* summation of 'nums' */
unsigned int i = 1; /* count to traverse all array keys */
unsigned int asize = limitasasize(t); /* real array size */
/* traverse each slice */
for (lg = 0, ttlg = 1; lg <= MAXABITS; lg++, ttlg *= 2) {
unsigned int lc = 0; /* counter */
unsigned int lim = ttlg;
if (lim > asize) {
lim = asize; /* adjust upper limit */
if (i > lim)
break; /* no more elements to count */
}
/* count elements in range (2^(lg - 1), 2^lg] */
for (; i <= lim; i++) {
if (!isempty(&t->array[i-1]))
lc++;
}
nums[lg] += lc;
ause += lc;
}
return ause;
}
重新确定数组大小的一个原则就是,数组中不为空的元素要超过数组长度的一半,Lua 的设计者使用这种方法保证效率和内存使用的平衡。函数 computesizes 用于计算新数组的大小,代码如下:
static unsigned int computesizes (unsigned int nums[], unsigned int *pna) {
int i;
unsigned int twotoi; /* 2^i (candidate for optimal size) */
unsigned int a = 0; /* number of elements smaller than 2^i */
unsigned int na = 0; /* number of elements to go to array part */
unsigned int optimal = 0; /* optimal size for array part */
/* loop while keys can fill more than half of total size */
for (i = 0, twotoi = 1;
twotoi > 0 && *pna > twotoi / 2;
i++, twotoi *= 2) {
a += nums[i];
if (a > twotoi/2) { /* more than half elements present? */
optimal = twotoi; /* optimal size (till now) */
na = a; /* all elements up to 'optimal' will go to array part */
}
}
lua_assert((optimal == 0 || optimal / 2 < na) && na <= optimal);
*pna = na;
return optimal;
}
如果计算出来的 newsize 大于原来的大小,则将 Node 数组(哈希部分)中的一部分移到数组之中;如果小于,则将数组的一部分移到 Node 数组中。但无论如何都要对 Node 部分进行 rehash 操作。
上文中的 numusearray 和 computesizes 计算都是在函数 rehash 中调用的:
/*
** nums[i] = number of keys 'k' where 2^(i - 1) < k <= 2^i
*/
static void rehash (lua_State *L, Table *t, const TValue *ek) {
unsigned int asize; /* optimal size for array part */
unsigned int na; /* number of keys in the array part */
unsigned int nums[MAXABITS + 1];
int i;
int totaluse;
for (i = 0; i <= MAXABITS; i++) nums[i] = 0; /* reset counts */
setlimittosize(t);
na = numusearray(t, nums); /* count keys in array part */
totaluse = na; /* all those keys are integer keys */
totaluse += numusehash(t, nums, &na); /* count keys in hash part */
/* count extra key */
if (ttisinteger(ek))
na += countint(ivalue(ek), nums);
totaluse++;
/* compute new size for array part */
asize = computesizes(nums, &na);
/* resize the table to new computed sizes */
luaH_resize(L, t, asize, totaluse - na);
}
next 操作
在 Lua 解释器中没有实现一个数据结构可以维护对 Table 的迭代信息,但是有一个函数 LuaH_next 可以通过传入一个键值,返回下一个键值对(实际上是将键值对压入 Lua 的栈中):
int luaH_next (lua_State *L, Table *t, StkId key) {
unsigned int asize = luaH_realasize(t);
unsigned int i = findindex(L, t, s2v(key), asize); /* find original key */
for (; i < asize; i++) { /* try first array part */
if (!isempty(&t->array[i])) { /* a non-empty entry? */
setivalue(s2v(key), i + 1);
setobj2s(L, key + 1, &t->array[i]);
return 1;
}
}
for (i -= asize; cast_int(i) < sizenode(t); i++) { /* hash part */
if (!isempty(gval(gnode(t, i)))) { /* a non-empty entry? */
Node *n = gnode(t, i);
getnodekey(L, s2v(key), n);
setobj2s(L, key + 1, gval(n));
return 1;
}
}
return 0; /* no more elements */
}
上述代码的基本思路为对传入 Key 之后的位置进行遍历,找到第一个非空的元素,将其键值对压入栈中,遍历依然是数组部分优先。
总结
通过对 Lua Table 的学习,发现它真的是一门很适合用于教学的语言:首先它的设计理念很统一,而且蕴含了 Less is more 等简洁哲学;其次,它的代码短小规范,结构清晰,可读性极强,技巧使用也不多,看 Lua 代码有一种坐在教室看幻灯片的感觉。
但做到了简洁,代价又是什么呢?
我认为 Table 反而丧失了数组的高效,也让字典的内部实现变得复杂了起来。不过作为一门广泛用于配置文件的胶水语言,效率也许并没有那么重要。