流水线级
一条流水线的每个分步骤被称为流水线级。它们被流水线寄存器分开。下文中没有说明是流水线寄存器的都是普通 CPU 寄存器。
现代计算机流水线级数已经达到了 10-20 级,在 2000-2010 年间,流水线级数的竞赛达到了最高峰,那时候的处理器甚至可以有高达 31 级的流水线。但是超深的流水线带来的是结构上的复杂和显著增大的动态调度模块设计难度,因此,从那以后就没有再出现过使用这么多级流水线的 CPU 了。
我们只是稍微介绍(或者说是为已经知道的同学前情回顾)一下最基础的 CPU 流水线,它有助于我们理解更为复杂的流水线实现。同时,这个最基础的 CPU 流水线并不基于某一架构,因此并不会涉及操作数的数量、对立即数的操作等信息。
取指(Instruction Fetch)
从内存中获取指令
- 每个周期从指令缓存中取一条指令
- 将状态写入流水线寄存器
译码(Instruction Decode)
读取寄存器并解码指令
- 解码操作数,为后续阶段设置不同标志
- 从寄存器文件中读取输入操作数,由所需操作数或指令指定(例如 push 隐含了对栈顶寄存器的操作)
- 将状态写入流水线寄存器(例如操作数、寄存器内容、立即数等)
执行(Execute)
执行指令
- 执行 ALU 运算,计算指令结果
- 将状态写入流水线寄存器(例如 ALU 计算结果等)
访存(Memory Access)
访问内存
- 执行数据缓存访问
- 将状态写入流水线寄存器(例如上一步得到的 ALU 计算结果和这一步获得的数据等)
写回(Write-Back)
将结果写入寄存器(如果该指令需要这么做的话)
- 将加载的数据写入目标寄存器
- 将 ALU 计算结果写入目标寄存器
设计和实现的问题
冒险(Hazard)
在流水线中我们希望当前每个时钟周期都有一条指令进入流水线可以执行。但在某些情况下,下一条指令无法按照预期开始执行,这种情况就被称为冒险。
数据冒险
一条指令需要某数据而该数据正在被之前的指令操作,这条指令就无法执行。
mov eax, 1
add ebx, eax
假设 CPU 不管任何数据冒险。那么当指令 add ebx, eax 来到译码阶段时,它的上一条指令,mov eax, 1 ,还处在执行阶段中。此时 mov eax, 1 还没有将立即数写入 CPU 寄存器,因此 add ebx, eax 无法读取到正确的 eax 内容。这时就出现了数据冒险。
控制冒险
当前应该执行的指令需要之前的指令运行结果来决定,这条指令就无法执行。
例如,当需要当前指令进入流水线时,上一条指令 je l1 尚未通过译码阶段,尚未读取条件码寄存器,不能确定下一条执行的指令。
结构冒险
一条指令需要的硬件部件还在为之前的指令工作,这条指令就无法执行。
例如,如果指令和数据放在同一个存储器中,则不能同时读存储器(一条指令正在从内存中取指令,另一条正在访存)。实际上,虽然冯诺依曼结构不区分指令和数据,但是在现代 CPU 的一级高速缓存(L1 cache)上,其实区分了指令(icache)和数据(dcache)。
又例如,读寄存器和写寄存器同时发生(一条指令正在写回,另一条正在译码)。可以通过前半个周期写,后半个周期读,并且设置独立的读写端口的方式来解决。
解决
解决冒险问题,很多时候采取的是给 CPU 增加更多的支路将不同流水线阶段连接起来的方法,但是由于不能将未来的数据传递到过去,所以除了「转发」操作还不得不使用「暂停」操作。
转发(Forwarding)
转发有时又叫旁路(Bypassing)
将结果值直接从一个流水线阶段传到较早阶段的技术就是数据转发。数据转发需要在基本的硬件结构中增加一些额外的数据连接和控制逻辑。
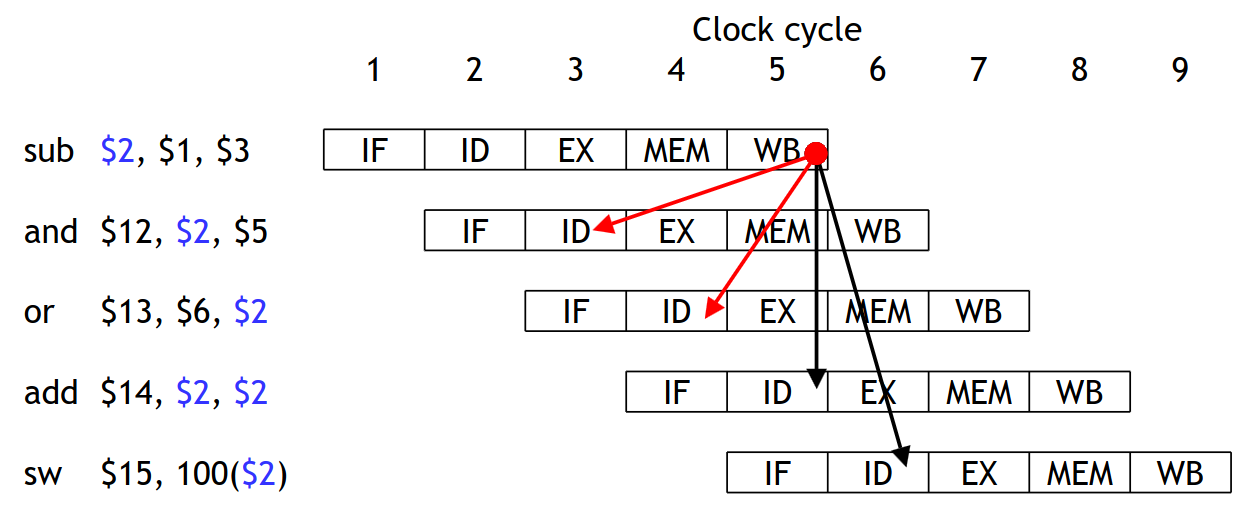
如上图所示,数据依赖导致了数据冒险,箭头表示依赖关系,红色箭头表示所依赖的数据此时尚未写回,黑色数据表示所依赖数据此时已经写回。
对于红色箭头,当 and 和 or 处于译码阶段,需要读取寄存器文件时,CPU 能发现在之前的 sub 指令中还有没有完成的寄存器写操作,然后通过数据转发直接获得 $2 的值。
暂停(Stall & Bubble)
暂停时,处理器会停止流水线的一条或多条指令,直到冒险条件不再满足。
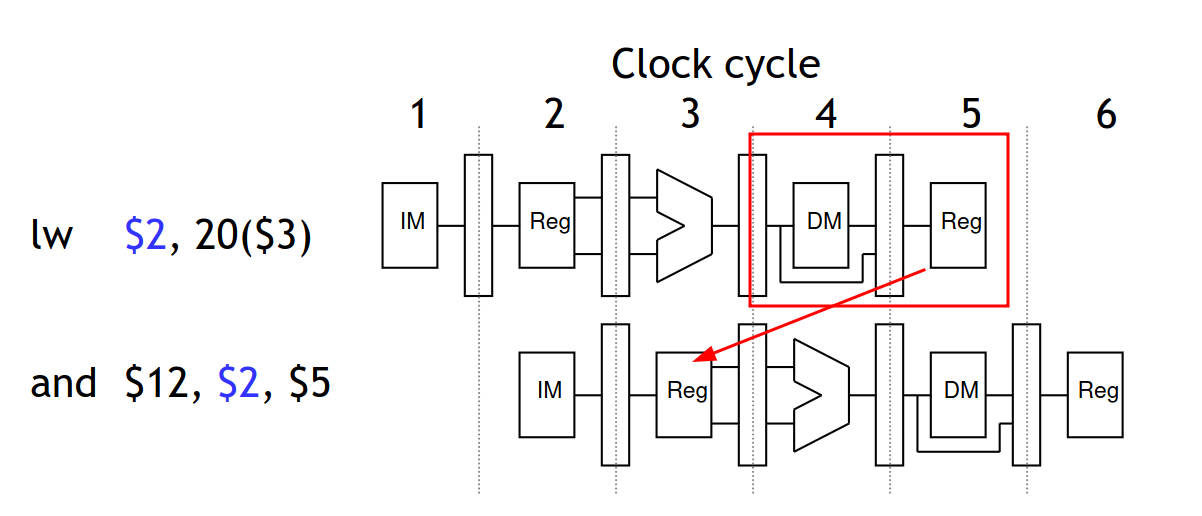
如上图所示,lw $2 20($3) 将内存中的数据加载到寄存器 $2 中,下一条指令使用了 $2 的值,因此产生了数据冒险。值得注意的是,这里寄存器的值最早也要在访存阶段获得,因此 and 指令无法通过数据转发的方式获得 $2 的值。
此时就不得不使用暂停的方法来处理冒险了。在这里处理器要暂停已经进入流水线的 lw 以后的所有指令。
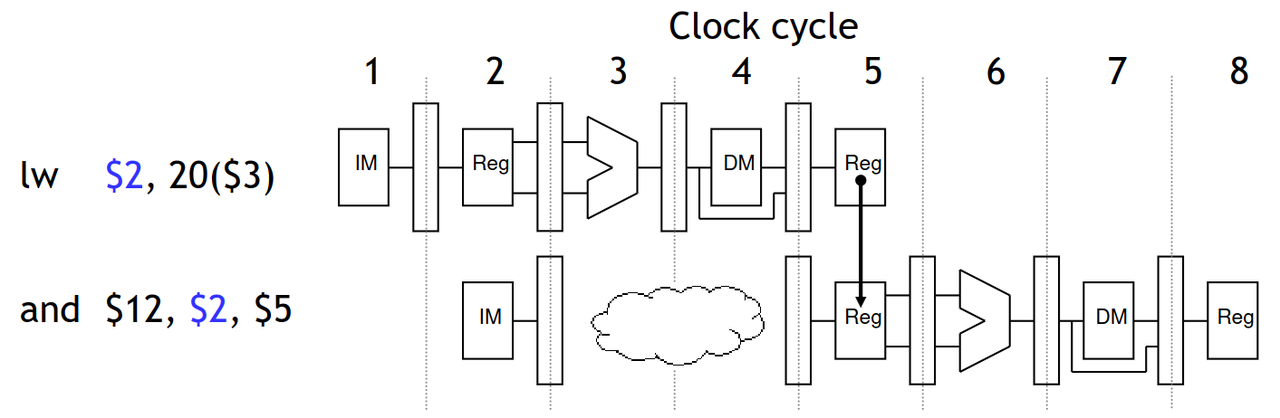
特别需要提醒的是,暂停虽然和指令 nop 有相同之处,但其本质是处理器内部处理数据冒险时自动添加的,而不是由编译器产生的。如果需要编译器产生 nop 指令来暂停,那代码将不能在相同平台的不同流水线级数的处理器上通用(比如有的需要 7 个 nop 指令能等待到冒险条件不满足,有的需要 9 个 nop 指令)。
分支预测
为什么要预测分支?
假设我们不预测分支,每当我们遇到控制冒险时都采用暂停的方法,我们需要等待一条指令完成执行阶段再对下一条取指。在前文的五段流水线 CPU 中,这会浪费两个周期。
而当我们预测分支时,当我们进入了错误的分支时,我们需要抛弃已经运行的结果重新取指(一般叫 flush),这样也是浪费两个周期。但是只要我们预测正确一次,那就必然比暂停的方法快。
目前所有的 CPU 都采用了分支预测的方法来处理控制冒险,现代 CPU 的分支预测准确率可以达到 90% 。